Ich fasse die Projektarbeit über die Stromerzeugungsanalyse der Windkraftanlagen der Welt seit 1980 zusammen, die ich als letzte Aufgabe der letzten Projektklasse geschrieben habe. Diese Projektarbeit wurde in Zusammenarbeit mit dem Institut IWES der Leibniz Uni Hannover verfasst, auf Basis der von Windpower bereitgestellten Daten analysiert und am 17. Mai 2022 endgültig eingereicht.
Ich hoffe, dass diese Analyse denjenigen, die sich mit Windenergie und Forschung befassen, eine gewisse Hilfe sein wird.
2. VIsuelle Darstellung von Daten
2.1. Datenbasis
Die Datenbanl-Datei für dieses Projekt wurde durch das Institut IWES (Institut für Windenergiesysteme) bereitgestellt. IWES hat die Daten auch von The „Wind Power“ erhalten und die Datei wurde am 7. Oktober 2021 beschrieben.
„Wind Power" ist ein Unternehmen mit Sitz in Tournefeulle in der Region Haute Garonne in Aquitanien im Südwesten Frankreichs und es kann eine umfassende Datenbank mit detaillierten Rohstatistiken über den schnell wachsenden Bereich der Windenergie und ihre unterstützenden Märkte versorgen. "Wind Power" tabelliert Daten von einer Vielzahl von Akteuren in der weltweiten Industrie – Windparkentwickler, Betreiber und Eigentümer, Turbinenhersteller, um nur einige zu nennen – in nutzbare Zahlen, die in den Formaten Excel, Csv, Tsv, Shape, Kmz und Kml verfügbar sind.
Diese Daten von "Wind Power" werden über einen rollierenden Zeitraum von sechs Monaten überprüft und überarbeitet. Außerdem werden die Daten ein-, zwei- oder dreijährige Update-Pakete auf jährlicher, halbjährlicher, vierteljährlicher oder monatlicher Basis angeboten. Auf der Anfrage können die Daten auch an infolge den genauen Marktanforderungen angepasst.[13] Daher wird davon ausgegangen, dass die von Windpower erstellten Daten für die aktuelle Zeit eine genaue Zuverlässigkeit aufweisen und der Fehler durch die regelmäßigen Aktualisierungen niedrig ist.

Die Windpark-Datenbank ist wie in Abb.2 oben insgesamt 27 Kategorien unterteilt. Der Hauptinhalt der Kategorie umfasst Informationen über den Standort des Windparks (Kontinent, Land, Stadt etc.) und geografische Informationen (wie Breitengrad, Längengrad). Darüber hinaus umfasst Informationen über die Details (Anlagentyp, Nummer, Nabenhöhe, Hersteller, Eigentümer etc.) und Total Power und zum Baujahr, die die wichtigsten Faktoren bei der Durchführung dieses Projekts sind. Darüber hinaus können detailliertere Informationen für jeden Windpark abgeruft, indem der Link geklickt werden, der zusammen unter Datum bereitgestellt wird. Für dieses Projekt konnte die Leistungsdichte berechnt werden, indem jeder Durchmesser separat von diesem Link weiter abgeleitet wird.
2.2. Konzept der Kartenstellung
Bevor diesem Projekt fortgefahren wird, wurde ein paar Muster zur Darstellung vn Daten recherchiert. Nicht nur neben dem Thema des Windes, sondern auch neben dem vielfältigen Thema wird die Methode der Datendarstellung auf der Karte eingesetzt. Deswegen konnte verschiedene Themen und Konzepte daneben entdeckt werden. Darunter wurden der drei typischsten und angenehmsten Musterstile die Stärken und Schwächen herausgearbeitet und versucht, eine für mein Vorhaben passende Methode umzusetzen. Die drei Musterstile sind wie in Abb.3 unten dargestellt.
Erster Stil wird mit Kreis gezeichnet und zweiter Stil mit jeweiligen Positionen und Farbe gezeichnet. Außerdem wird der letzte Stil mit unterschiedlicher Farbe gezeichnet. Jede der oben genannten drei Methoden hat Vor- und Nachteile. Je nachdem, welches Thema zum Ausdruck kommt, sollten daher verschiedene Stile berücksichtigt werden.
Zunächst hat der erste Stil den Nachteil, dass es schwierig ist, den Standort jedes Windparks auszudrücken. Es hat jedoch den Vorteil, dass es für vergleichende Analysen geeignet ist, da Punkte mit unterschiedlichen Größen und unterschiedlichen Farben je nach Bedingungen hergestellt werden können. Außerdem hat es den Vorteil, dass das Vergleichsobjekt etwas übersichtlicher wird, weil es ausgedrückt werden kann, indem man die Bedeutung des Punktes an jedem Punkt in Stichpunkt schreibt. Daher ist es für die Darstellung des jeden Status nicht geeignet, wurde aber als geeignet für den Ländervergleich beurteilt.
Der zweite Stil hat Vor- und Nachteile gegenüber dem oben diskutierten ersten Stil. Da jedes Objekt als Punkt ausgedrückt wird, hat es den Nachteil, dass es nicht zum Vergleich des Gesamtstatus geeignet ist, aber es hat den Vorteil, dass es dazu geeignet ist, einfach den jeden Status auszudrücken. Darüber hinaus hat es eine Möglichkeit, nicht nur die Position jedes Objekts auszudrücken, sondern auch einzelne Objekte durch unterschiedliche Konzentrationen und Größen zu vergleichen. Daher wurde beurteilt, dass es geeignet ist, den Gesamtstatus von Windparks in der Welt oder in dem zu identifizierenden Land zu erfassen. Durch diese Art von Landkarte können Sie die ungefähre Lage des Standorts und den Unterschied in der Dichte des Windparks bzw. der WEA erfassen.
Der dritte, letzte Stil hat die gleichen Vor- und Nachteile wie der erste. Im Falle eines Vergleichs mit Farbe ist es jedoch nicht möglich, die Bedeutung jeder Farbe oder Dichte klar zu verstehen, und es gibt einen zusätzlichen Nachteil, dass die Bedeutung jeder Farbe durch Legende separat verstanden werden muss.
Jeder der oben beschriebenen Vor- und Nachteile kann in der folgenden Tab.1 kurz beschrieben werden.
Nach diesen drei Musterstile-Überlegungen wurde der dritte Stil in diesem Projekt nicht berücksichtigt, und wurde zum ersten Stil dargestellt. Auch bei der Landkarte, die einzelne Windparkpositionen anzeigt, wurde der zweite Musterstil verwendet, wie oben beschrieben. Der ist für spätere Detailanalysen (Entwicklungsverlauf nach Jahr etc.) von Ländern wie Deutschland und Dänemark hilfreich. Entsprechend dieser Betrachtung der Ausdrucksmethode wurde die Methode der Darstellung gewählt und zusätzlich eine für jede Analyseaufgabe geeignete Form ausgewählt und durch zusätzliche Modifikationen implementiert.
2.3. Umsetzung der Karten
2.3.1. Flussdiagramm
Die Arbeitsschritte für das Projekt verlaufen wie im Flussdiagramm [Abb.4] Die Arbeit beginnt mit der Übernahme der Datenbank, die oben im Kapitel 2. beschrieben wurde. Beim Erwerb von Daten wurden diese nach einer Zusage zur Wahrung der Sicherheit und zur Nichtwiederverwendung erworben. Die erforderlichen Parameter unter den 27 Parametern von der Daten wird eingestellt und mit der Analyse fortgefahren.
Danach wurde zur Datenanalyse das Programm Python verwendet. Die Software, die hauptsächlich für die Analyse im Engineering-Bereich verwendet wird, sind sowohl Python als auch Matlab, C/C++, und R. Darunter sind im Allgemeinen zwei Programme, Matlab und Python, bekannt, um die typischen Landkarten zu erzeugen. Diese beiden Programme sind interpretierte Programmiersprachen, die Zeile für Zeile von einem Interpreter interpretiert und ausgeführt werden, nicht von einem Compiler, und haben den Vorteil, dass sie Programme leicht debuggen können, obwohl die Ausführungszeit langsam ist. Außerdem ist im Vergleich zu C/C++ es das leicht zugänglich, da es nicht schwer zu debuggen ist.
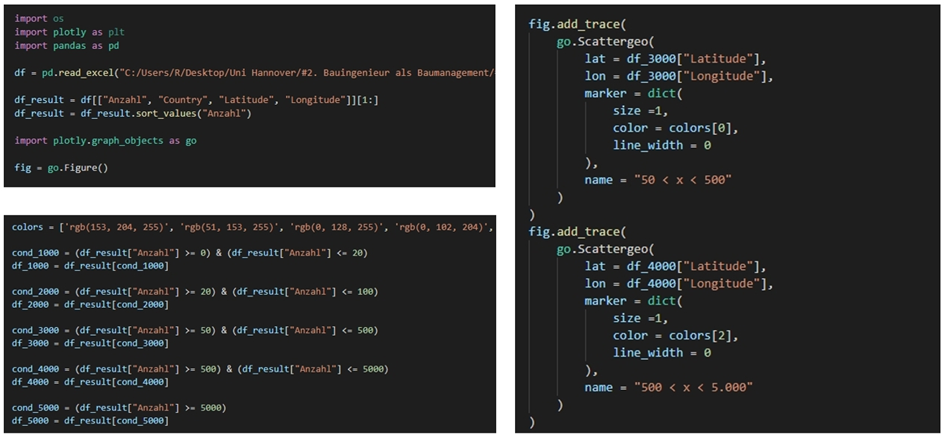
Unter anderem habe ich diese Implementierung mit Python durchgeführt. Beide Programme, Python und Matlab, haben ihre eigenen Vor- und Nachteile, aber Python wurde unter Berücksichtigung verschiedener Aspekte ausgewählt. Der Grund dafür ist, dass Python Numpy, das effizient mit mehrdimensionalen Arrays umgehen kann, und Scipy, das auf wissenschaftliche Berechnungen und numerische Analysewerkzeuge spezialisiert ist, hat. Außerdem hat Python eine Möglichkeit bzw. einen Vorteil durch Matplotlib, das Funktionen bietet, die fast identisch mit der Graphfunktion von Matlab sind, dass es genug Funktionen bekommen kann, etc. Mit anderen Worten, obwohl die Verwendung von Pythons Funktionen mit Matlab begrenzt wird, gibt es viele Pakete, die Matlabs Funktionen mit Python verwenden können. In diesem Projekt habe ich kein Paket wie Numpy oder Scipy verwendet, aber es war attraktiv, dass es viele funktionale Vorteile hatte. Darüber hinaus begann Matlab mit einer Bibliothek der linearen Algebra und erweiterte seinen Anwendungsbereich durch die Bereitstellung von Toolboxen in verschiedenen Bereichen, aber Python ist eine objektorientierte Allzweck-Programmiersprache und lässt sich einfach in Kombination mit anderen Sprachen wie Fortran verwenden. Deswegen hat es den Vorteil, dass Bibliotheken, die bereits in anderen Sprachen entwickelt wurden, problemlos verwendet werden können. Vor allem die Python-Sprache selbst entwickelt sich immer noch weiter, und es werden kontinuierlich kostenlose Pakete in verschiedenen Bereichen entwickelt. Auf diesen Gründe wurde Python mit diesem Projekt verwendet und damit bearbeitet.
Insbesondere ein Paket namens Pandas, abgeleitet von „Python and Data Analysis“ und „panal Data“, ist ein Python-Modul, das die Funktionalität von Numpy, Scipy und Matplotlib vervollständigt. Pandas ist eine für Python geschriebene Softwarebibliothek, die im Jahr 2008 von Wes McKinney bei AQR Capital Management entwickelt wurde. Pandas wird hauptsächlich zur Datenmanipulation und -analyse verwendet, insbesondere. Es stellt spezielle Funktionen und Datenstrukturen zur Manipulation numerischer Tabellen und Zeitreihen zur Verfügung, die aktuell neueste Version ist 1.4.1.
Die Vorteile von Pandas sind:
- als Open-Source-Software frei verfügbar und für jeden zugänglich
- voll in die Python-Umgebung integriert
- einfach zu erlernen und anzuwenden
- nutzbar mit vielen weiteren datenwissenschaftlichen Python-Bibliotheken (Ladung der Daten aus verschiedenen Dateiobjekten möglich)
- Einfache Handhabung fehlender Daten (dargestellt als NaN) in Fließkomma- und Nicht-Fließkomma-Daten
- performante Bearbeitung großer Datenmengen und großer Funktionsumfang
- flexibel für viele verschiedene Zwecke einsetzbar
- plattformunabhängig
- Unterstützung zahlreicher Datenformate
2.3.2. Parameter der Visualisierung
Visualisierungen werden durch die Analyse jedes Windparks basierend auf Gesamtleistung und Anzahl durchgeführt und berechnet zusätzlich die Anzahl der Windparks in jedem Land und die Gesamtgesamtleistung, damit ein Vergleich durchgeführt werden kann. Jede Methode zur Optimierung der entsprechenden Landkarte in der Visualisierung wird in 2.2 beschrieben. Darüber hinaus wurde jede Information als verschiedene Muster zur Implementierung betrachtet, damit Leser sie auf einen Blick einfach verstehen können.
2.3.3. Schwierigkeiten und Beschränkungen
Bei der Visualisierung von Landkarte durch Python wurden einige Schwierigkeiten und Probleme aufgrund des Hintergrunds des Programms gestoßen. Einige dieser Probleme wurden durch nachträgliche Bearbeitung behoben, aber aufgrund der Eigenschaften des Programms gibt es einige ungelöste Teile.
Zunächst geht es um den Fehler des Landes des Windparks aufgrund der unterschiedlichen Genauigkeit der Hinterkarte. Die durch Python generierte Landkarte hat eine vereinfachte Grenzgenauigkeit als Karten in Google Maps. Deswegen wurde, wie in Abb.6 unten zu sehen ist, ein Problem darin gefunden, dass sich Windparks in einigen Grenzgebieten befindliche in einem Nachbarland und nicht im entsprechenden Land befanden. Die Genauigkeit der in Python erstellten Grenzen auf der Landkarte ist unbearbeitbar, daher konnte dieses Problem nicht gelöst werden.
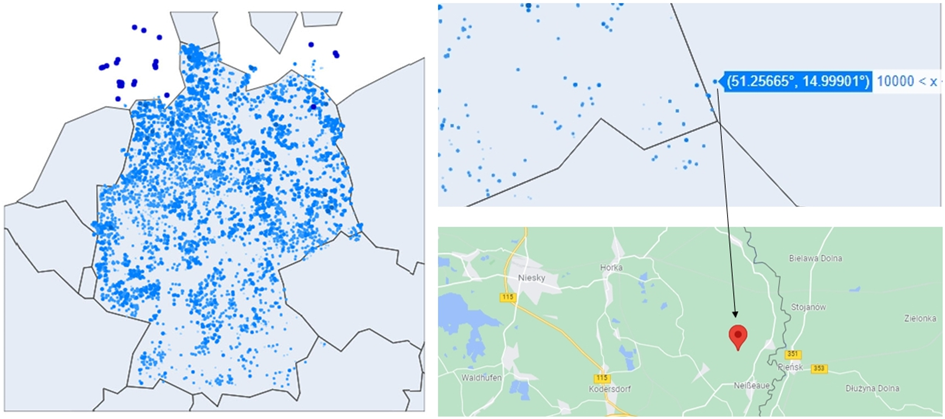
Beim Vergleich des problematischen Windparks in Bezug auf Breiten- und Längengrad wurde jedoch bestätigt, dass der Standort eindeutig implementiert wurde. Basierend auf dieser Analyse ist ein Fehler in der Standortausgabe von Windpark durch Python aufgetreten, aber dies ist schwer als Fehler in der Standortbestimmung von Windpark-Daten einzugestehen. Daher gibt es keine Grundlage für die Beurteilung, dass es der Genauigkeit von Daten an Zuverlässigkeit mangelt.
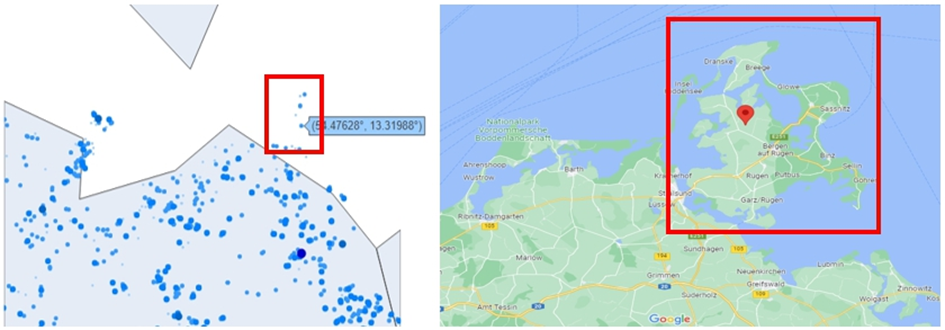
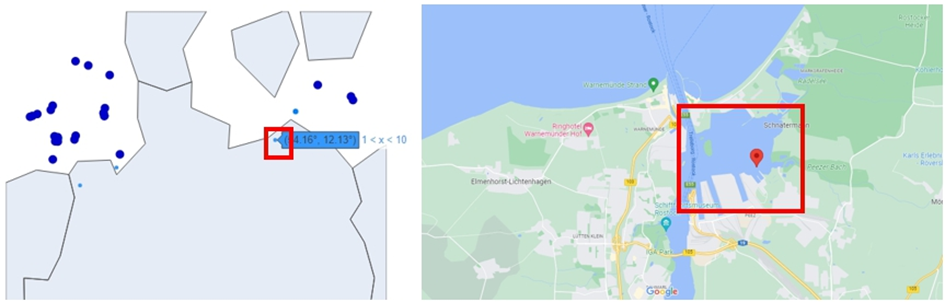
Das gleiche Problem tritt deutlich in den Analysen von Deutschland und Dänemark in Kapitel 3 und 4 unten auf. Für eine detaillierte Analyse der Windparks bzw. WEA in Deutschland und Dänemark wurden Onshore- und Offshore-Windparks aufgeteilt, um herauszufinden, welcher Entwicklungsprozess und Trend zeigen. In diesem Fall ergibt sich ein Standortproblem. Im Falle Deutschlands scheinen die auf den Ostseeinseln wie Rügen (siehe Abb.7) und Fehmarn errichteten Windparks auf dem Meer wie Offshore markiert zu sein, obwohl der Standort Onshore ist. Dies ist insofern ein Problem, als die Grenze zwischen dem Meer und dem Land, beispielsweise einer Insel, in der Hinterkarte, die in Python gedruckt ist, ungenau oder nicht ausgedrückt ist. In ähnlicher Weise wird Offshore aufgrund fehlender Details an Orten wie Hafen Rostock (Siehe. Abb.8), Dollard oberhalb der Ems als an Land gelegen gekennzeichnet. Aufgrund dieses Problems tritt bei in Python erstellten Landkarten das Problem auf, dass Onshore auf dem Meer und Offshore auf Land angezeigt wird und die Landkarte kann falsch beurteilt wurden, ob diese Information ungenau oder unglaublich sind oder ein Fehler während der Visualisierung passiert ist.
In Dänemark ist das Problem noch ausgeprägter. Dänemark besteht aus der Halbinsel Jütland und großen und kleinen Inseln. Unter diesen Inseln ist Sjælland (Zealand), wo sich die Hauptstadt Kopenhagen befindet, gezeichnet, aber die anderen Inseln sind nicht gezeichnet. Wie in Abb.9 unten gezeigt, gibt es viele Offshore-Anlagen, die auf den Inseln Fyn und lolland zwischen der Halbinsel Jütland und der Insel Sjælland gebaut wurden, als ob sie auf dem Meer lägen.
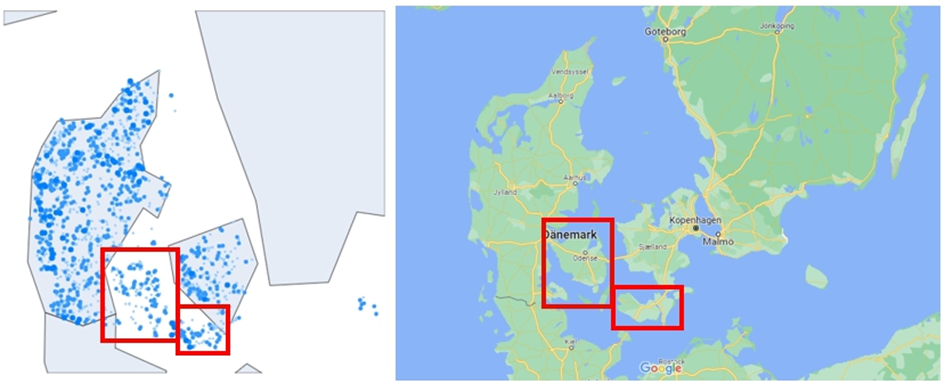
Obwohl eine solche visuelle Undeutlichkeit existiert, ist es kein Problem von Daten selbst, sondern eher die Undeutlichkeit, die bei der Realisierung von Visualisierung mit Python auftritt. Dies beweist nicht, dass die Genauigkeit von Daten zweideutig ist. Wenn daher eine Visualisierung implementiertieren wird, bleibt die Lösung dieses Problems die größte Herausforderung. Dazu wurde verschiedene Versionen von Python-Programmen wie Visual Code und Jupiter Python ausprobiert, aber das Ergebnis war das gleiche. Außerdem gibt es eine Möglichkeit, ein separates Paketprogramm wie Geojson zu verwenden. Aber in diesem Projekt war es wegen der zeitlichen und technischen Beschränkung unmöglich.
Außerdem besteht der Nachteil, dass ein Bereich der Landkarte Hintergrund nicht behoben werden können, außer für die 6 Elemente (World, Asia, Europa, Africa, Asia, North America, South America), die von Python während des Scoping-Prozesses festgelegt wurden. Wenn beispielsweise beispielsweise Ozeanien oder Amerika als einzelne Karte im Vergleich nach Kontinenten anzeigen möchten oder eine Karte eines Landes in Deutschland erstellen möchten, ist es unmöglich, als einem festen Kartenbereich zu zeigen. Deswegen muss der Bereich dafür nach der Auswahl eines anderen Elements den Hintergrund durch Vergrößern/Verkleinern suchen und einstellen. Mit diesem Prozess ist dies kein Problem für die Erstellung einer einzelnen Karte, aber es wird ein Problem, wenn Sie mehrere Karten mit unterschiedlichen Parametereinstellungen (z. B. Entwicklungsverlauf des Landes oder Kontinentes) für denselben Bereich auswählen müssen.
Das vollständige Papier (Analye des Windenergiebaus seit 1980 / Deutsch) finden Sie in der Datei unten.
Außerdem können Sie den Inhalt der einzelnen Kapitel im folgenden Beitrag überprüfen. (wird später aktualisiert)
0. Kurzfassung, Zusammenfassung und Ausblick
https://herr-kwak.tistory.com/1097
Analyse des globalen Windenergieausbaus seit 1980 / Kurzfassung, Zusammenfassung und Ausblick - (1980년 이후 세계적인 풍
Ich fasse die Projektarbeit über die Stromerzeugungsanalyse der Windkraftanlagen der Welt seit 1980 zusammen, die ich als letzte Aufgabe der letzten Projektklasse geschrieben..
herr-kwak.tistory.com
1. Einführung
https://herr-kwak.tistory.com/1100
Analyse des globalen Windenergieausbaus seit 1980 / Einleitung - (1980년 이후 세계적인 풍력시설의 발전 분석)
Ich fasse die Projektarbeit über die Stromerzeugungsanalyse der Windkraftanlagen der Welt seit 1980 zusammen, die ich als letzte Aufgabe der letzten Projektklasse geschrieben..
herr-kwak.tistory.com
3.1. Windparkenergieausbaus in Deutschland seit 1980 als Onshore
3.2. Windparkenergieausbaus in Deutschland seit 1980 als Offshore
4.1. Windparkenergieausbaus in Dänermark seit 1980 als Onshore
4.2. Windparkenergieausbaus in Dänermark seit 1980 als Offshore
5. Weltweite Windparks
Danke fürs Lesen.